Universal Correspondence Network
TL;DR: Universal Correspondence Network proposed the first fully convolutional way to learn contrastive embeddings for correspondences.
Notice
An open-source UCN available at github link.
In this post, we will give a very high-level overview of the paper in layman’s terms. I’ve received some questions regarding what the Universal Correspondence Network (UCN) is and the limitations of it. This post will answer some of the questions and hopefully facilitate research on derivatives applications of correspondences.
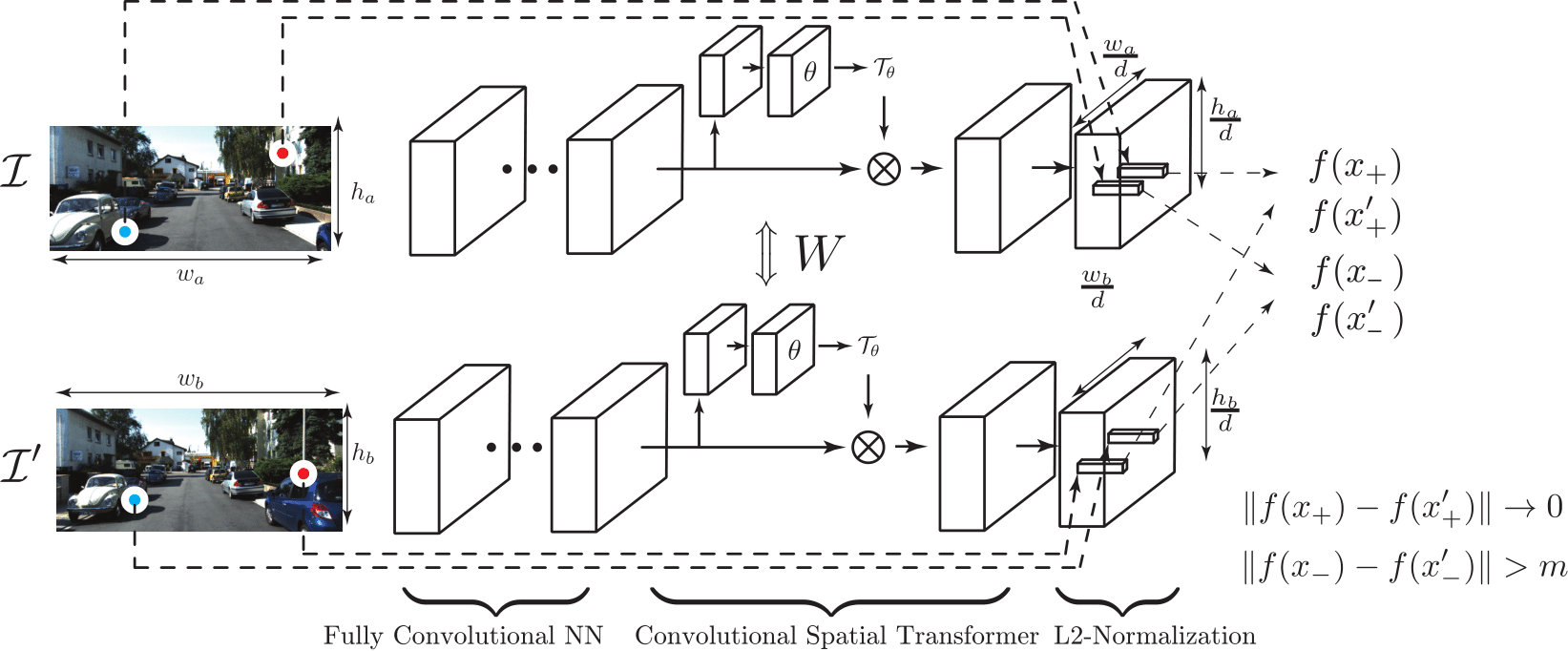
Patch Similarity
Measuring the similarity of image patches is a basic element of high level operations, such as 3D reconstruction, tracking, registration, etc. The most common and widely used patch similarity is probably “geometric similarity”. In the geometric similarity, we are interested in finding image patches from two different cameras of the same 3D point.
For instance, in stereo vision, we are observing a scene from two different cameras. Since the cameras are placed a certain distance apart, images from two cameras give us different observations of the same scene. We are interested in finding image patches from respective viewpoints that correspond to the same 3D point in the scene.
Another type of similarity is “semantic correspondence”. As the name suggests, in this problem, we are interested in finding the same semantic parts. For instance a left paw of a dog and a left paw of a cat are semantically, and functionally equivalent. In the semantic similarity, we are interested in finding image patches of the same semantic object.
Measuring Patch Similarity
Traditionally, measuring similarity is done by measuring the distance of features extracted from corresponding image patches. However, such features require a lot of hand design and heuristics which results in sub-optimal performance. After the series of successes of CNNs on replacing a lot of hand-designed steps in Computer Vision applications, CNN-base similarity measures have been introduced as well.
In CNN base patch similarity measure, a Convolutional Neural Network takes two image patches as inputs and generates a score that measures the likelihood of the patch similarity. However, since the network has to take both patches, the time complexity of the comparison is $O(N^2)$ where $N$ is the number of patches.
Instead, some methods cache the CNN outputs for each patch and only use Fully Connected layer feed forward passes $O(N^2)$ times. Still, the neural network feed forward passes are expensive compare to simple distance operations.
Another type of CNN uses intermediate FC outputs as surrogate features, but metric operations (distance) on this space is not defined. In another word, the target task of such neural networks is based on metric operation (distance), but the neural network does not know the concept when it is trained.
Universal Correspondence Network
To improve all of points mentioned in the previous section, we propose incorporating three concepts into a neural network.
- Deep Metric Learning for Patch Similarity
- Fully Convolutional Feature Extraction
- Convolutional Spatial Transformer
Deep Metric Learning for Patch Similarity
To minimize the number of CNN feed forward passes, many researchers introduced various techniques. In this paper, we propose using deep metric learning for patch similarity. Metric Learning is a type of learning algorithm that allows the ML model to form a metric space where metric operations are interpretable (i.e. distance). In essence, metric learning starts from a set of constraints that forces similar objects to be closer to each other and dissimilar objects to be at least a margin apart. Since the distance operations are encoded in the learning, using distance during testing (target task) yields meaningful results.
(Disclaimer) During the review process, Li et al.1 independently proposed combining metric learning with a neural network for patch similarity. However, the network is geared toward reconstruction framework and uses patch-wise feature extraction, whereas the UCN uses Fully Convolutional feature extraction.
Fully Convolutional Feature Extraction
Unlike previous approaches where CNNs only takes a pair of fixed-sized patches, we propose a fully convolutional neural network to speed up the feature extraction. Advantage of using a fully convolutional neural network is that the network can reuse the computations for overlapping image patches (Long et al.2).
For example, if we extract image patches and use a patch-based CNN, even if there is an overlap among patches, we have to compute all activations again from scratch. Whereas if we use a fully convolutional neural network, we can reuse computation for all overlapping regions and thus can speed up computation.
However, this may leads to fixed fovea size and rotation which can be fixed by incorporating the spatial transformer network (next section).
Convolutional Spatial Transformer Layer
One of the most successful hand-designed features in Computer Vision is probably the SIFT feature (D. Lowe3). Though the feature itself is based on pooling and aggregation of simple edge strengths, the way the feature is extracted is also a part of the feature and affects the performance greatly.
The extraction process tries to normalize features so that the viewpoint does not affect the feature too much. This process is the patch normalization. Specifically, given a strong gradient direction in an image patch, the feature find the optimal rotation as well as the scale and then computes features using the right coordinate system using the optimal rotation and scale. We implement the same idea in a neural network by adopting the Spatial Transformer Network into the UCN (Jaderberg et al.4). The UCN, however, is fully convolutional and the features are dense. For this, we propose the Convolutional Spatial Transformer that applies independent transformation to each and every feature.
What UCN can and cannot do
We designed a network for basic feature extraction and basic feature extraction only. This is not a replacement for high-level filtering processes that use extra supervision/inputs such as Epipolar geometry. Rather, we provide a base network for future research and thus the base network should not be confused with a full blown framework for a specific application.
One of the questions that I got at NIPS is why we did not compare with stereo vision. This question might have arisen because we used stereo benchmarks to measure the performance of the raw features for geometric correspondence task. However, as mentioned before, the raw feature does not use extra inputs and is not equivalent to a full system that makes use of extra inputs and constraints specific for stereo vision: Epipolar Line search, which significantly reduces the search space from an entire image to a line, and post processing filtering stages. More detailed explanation is provided in the following section.
Stereo Vision
For the baseline comparisons, we did not use full systems that make use of extra inputs: camera intrinsic and extrinsic parameters. If you remember how painful the cameras calibrationl was when you took a Computer Vision class, you might see that camera extrinsic parameters and intrinsic parameters are strong extra inputs. Further, such extra inputs allow you to drastically reduce the search space for geometric correspondence.
Such constraint is known as the Epipolar constraint and is a powerful constraint that comes at a price. Since our framework is not a specialized for a stereo vision, we did not compare with systems that make use of this extra input/supervision.
Instead, we use all latest hand-designed features, FC layer features, and deep matching5 since all of those do not use extra camera parameters. In this paer, we focus only on the quality of the features that can be used for more complex systems.
In addition, in UCN, to show the quality of the feature, we simply used the most stupid way to find the correspondence: nearest neighbor on the entire images, which is very inefficient, but shows the quality of the raw features. To be able to compare it with the stereo vision systems, extra constraints (Epipolar geometry + CRF filtering) should be incorporated into both training and testing.
Conclusion
We propose an efficient feature learning method for various correspondence problems. We minimized the number of feed forward passes, incorporated metric space into a neural network, and proposed a convolutional spatial transformer to mimic behavior of one of the most successful hand designed features. However, this is not a replacement for the more complex system. Rather, this is a novel way to generate base features for a complex system that require correspondences as an input. I hope this blog post had resolved some of the questions regarding the UCN and facilitated future research.



Leave a Comment