3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
Abstract
Inspired by the recent success of methods that employ shape priors to achieve robust 3D reconstructions, we propose a novel recurrent neural network architecture that we call the 3D Recurrent Reconstruction Neural Network (3D-R2N2). The network learns a mapping from images of objects to their underlying 3D shapes from a large collection of synthetic data~\cite{shapenet}. Our network takes in one or more images of an object instance from arbitrary viewpoints and outputs a reconstruction of the object in the form of a 3D occupancy grid. Unlike most of the previous works, our network does not require any image annotations or object class labels for training or testing. Our extensive experimental analysis shows that our reconstruction framework i) outperforms the state-of-the-art methods for single view reconstruction, and ii) enables the 3D reconstruction of objects in situations when traditional SFM/SLAM methods fail (because of lack of texture and/or wide baseline).
3D-R2N2: 3D Recurrent Reconstruction Neural Network
This repository contains the source codes for the paper Choy et al., 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction, ECCV 2016. Given one or multiple views of an object, the network generates voxelized ( a voxel is the 3D equivalent of a pixel) reconstruction of the object in 3D.
Citing this work
If you find this work useful in your research, please consider citing:
@inproceedings{choy20163d,
title={3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction},
author={Choy, Christopher B and Xu, Danfei and Gwak, JunYoung and Chen, Kevin and Savarese, Silvio},
booktitle = {Proceedings of the European Conference on Computer Vision ({ECCV})},
year={2016}
}
Overview
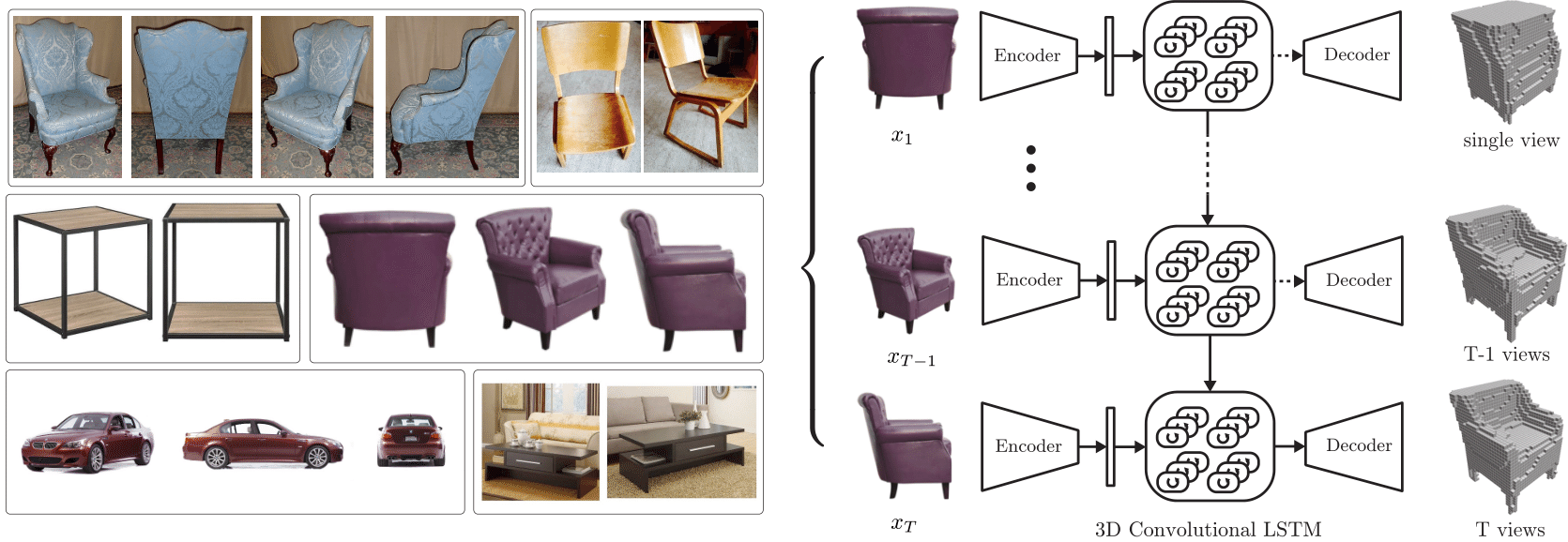 Left: images found on Ebay, Amazon, Right: overview of
Left: images found on Ebay, Amazon, Right: overview of 3D-R2N2
Traditionally, single view reconstruction and multi-view reconstruction are disjoint problems that have been dealt using different approaches. In this work, we first propose a unified framework for both single and multi-view reconstruction using a 3D Recurrent Reconstruction Neural Network (3D-R2N2).
| 3D-Convolutional LSTM | 3D-Convolutional GRU | Inputs (red cells + feature) for each cell (purple) |
|---|---|---|
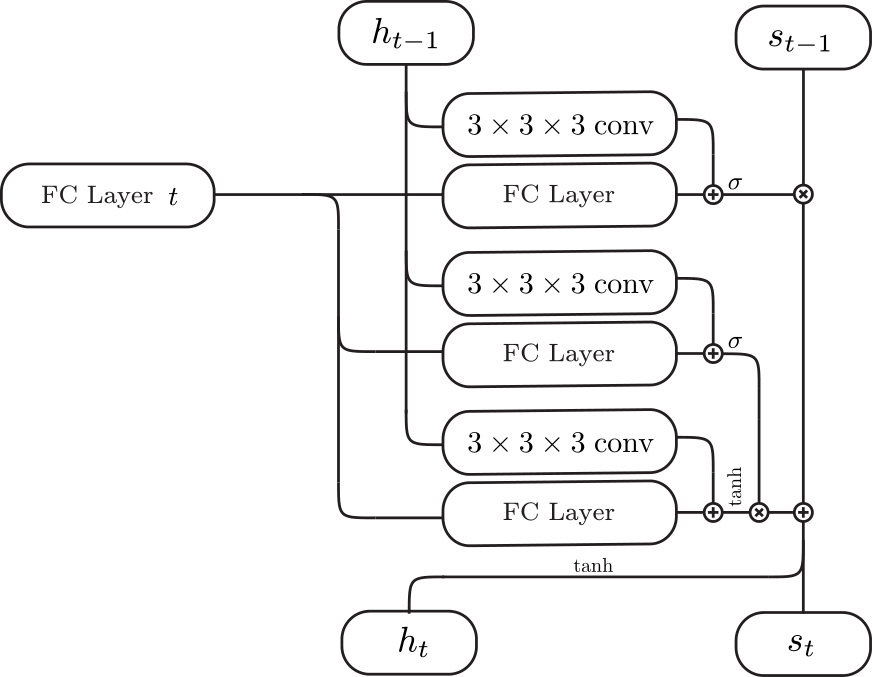 | 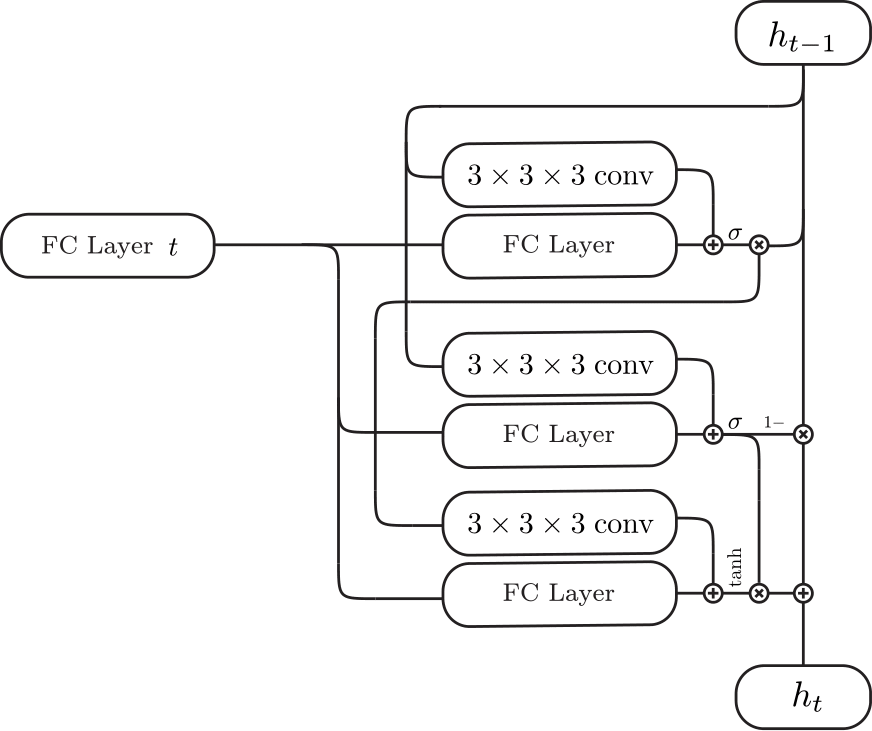 | 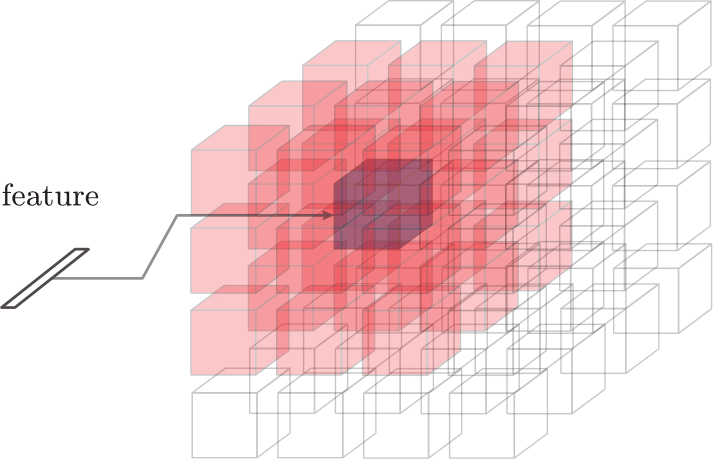 |
We can feed in images in random order since the network is trained to be invariant to the order. The critical component that enables the network to be invariant to the order is the 3D-Convolutional LSTM which we first proposed in this work. The 3D-Convolutional LSTM selectively updates parts that are visible and keeps the parts that are self-occluded.
 Visualization of the 3D-Convolutional LSTM input gate activations. The images are fed into the network sequentially from left to right (top row). Visualization of input gate activations. The input gates corresponding to the parts that are visible and mismatch prediction open and update its hidden state (middle row). Corresponding prediction at each time step (bottom row).
Visualization of the 3D-Convolutional LSTM input gate activations. The images are fed into the network sequentially from left to right (top row). Visualization of input gate activations. The input gates corresponding to the parts that are visible and mismatch prediction open and update its hidden state (middle row). Corresponding prediction at each time step (bottom row).
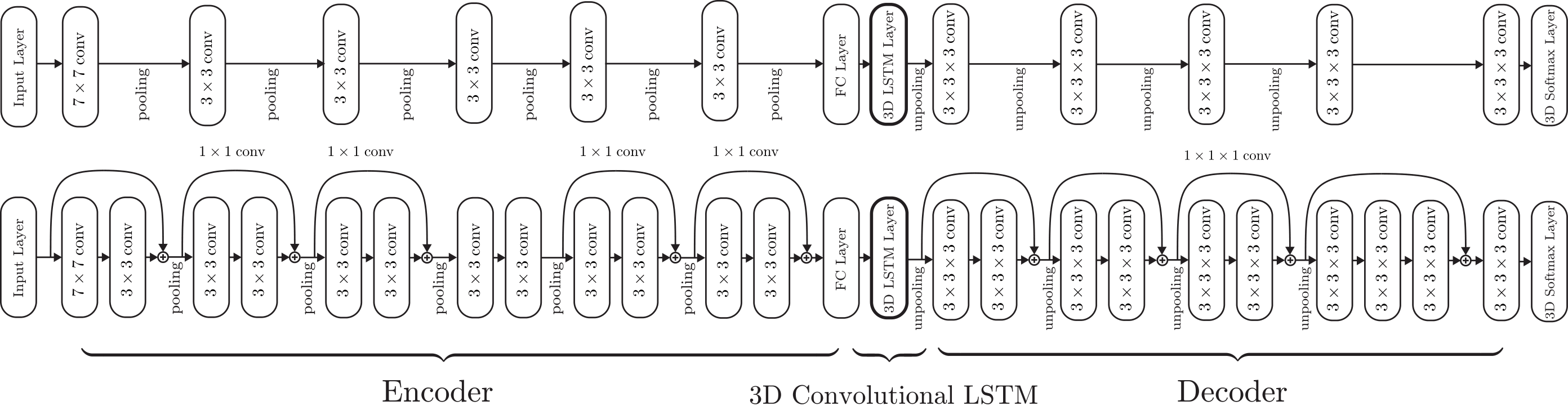 We used two different types of networks for the experiments: a shallow network (top) and a deep residual network (bottom).
We used two different types of networks for the experiments: a shallow network (top) and a deep residual network (bottom).
Datasets
We used ShapeNet models to generate rendered images and voxelized models which are available below (you can follow the installation instruction below to extract it to the default directory).
- ShapeNet rendered images ftp://cs.stanford.edu/cs/cvgl/ShapeNetRendering.tgz
- ShapeNet voxelized models ftp://cs.stanford.edu/cs/cvgl/ShapeNetVox32.tgz
Codes
The source codes for the project can be found at the .



Leave a Comment